
\Demis Hassabis (DeepMind CEO) and other AI leaders sees the next big AI gains—and the path to AGI—will come from targeted algorithmic breakthroughs in areas like continual learning, memory architectures, world models, reasoning/planning, and hybrid systems. Demis talked in a 20VC podcast with Harry Stebbings.
Here’s a structured summary drawn from that interview, his other 2025–2026 statements (podcasts, DeepMind announcements), and the frontier research landscape.
1. Hassabis’ core views from the video and recent talks
– Biggest bottlenecks today Compute/energy is the obvious limiter for scaling, but the deeper issues are architectural and algorithmic. Models lack consistency, long-horizon reliability, and human-like adaptability.
– Scaling laws have NOT hit the limits. LLMs will not commoditize easily. Push scaling (pre-training, post-training, and especially inference-time compute) to the absolute maximum will be a key component of AGI. However, it’s ~50/50 whether scaling alone suffices or if 1–2 more breakthroughs are needed. DeepMind allocates roughly half its resources to blue-sky algorithmic innovation and half to maximal scaling.
– What’s still missing are one or two breakthroughs
– Continual/online learning Systems that learn continuously in the wild (post-training, from new experiences) without catastrophic forgetting or needing full retraining. Humans do this effortlessly; current models don’t. Hassabis calls this critical for personalization and real-world adaptation
– Long-term memory / hierarchical memory Beyond fixed context windows—persistent, efficient memory that supports long-horizon reasoning and identity across sessions.
– World models Internal simulations that understand physics, causality, materials, object behaviors, and “how the world works.” These enable planning, imagination, and grounded interaction (not just next-token prediction).
– Advanced reasoning & hierarchical planning Consistent, multi-step thinking (System 2) rather than pattern-matching. Merging LLMs with search/planning (AlphaZero-style Monte Carlo Tree Search or RL) is a promising hybrid direction.
– Other leaders align closely
– Yann LeCun (Meta) heavily pushes world models (JEPA/V-JEPA family) for predictive, grounded intelligence over pure language modeling.
– Broader consensus (Altman, Amodei, Karpathy, Dean) echoes the shift to inference-time scaling, agentic loops, memory augmentation, and closing the reality gap via simulation.
Hassabis views AGI as plausible in the next 5–10 years (roughly 2030–2035 window, with a distribution around the lower end), driven by these advances plus relentless progress on Gemini-like models. He sees it as 10× bigger/faster than the Industrial Revolution.
2. Key frontier papers & improvements (2025–early 2026)
Research has accelerated exactly in the areas Hassabis flags.
AI is moving beyond static transformers to dynamic, memory-augmented, self-modifying, and world-simulating systems. Gains are algorithmic efficiency, new inductive biases. This is beyond just scale.
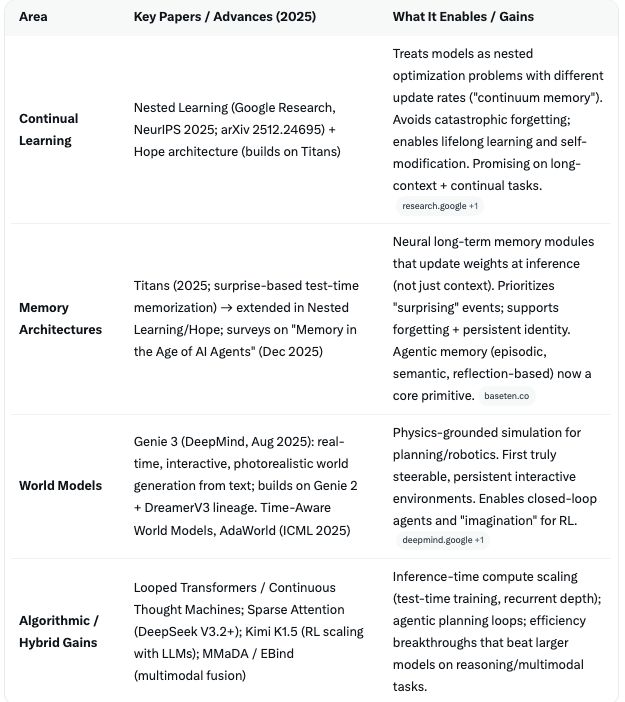
Algorithmic efficiency gains are already compounding.
New architectures deliver 4–17× effective performance over raw scaling in some domains (memory, reasoning). Test-time compute (letting models think longer) and hybrid RL/search are where the biggest short-term wins are appearing.
3. Where scaling laws still deliver gains
Hassabis and labs (OpenAI, Anthropic, Google) agree pre-training, post-training, and especially inference-time scaling have substantial headroom through at least 2027–2028.
Returns are not zero yet—frontier models like Gemini 3 show relentless progress.
However, diminishing returns on pure pre-training data/compute push the field toward:
– Inference scaling (o1-style reasoning chains, test-time training).
– Multimodal + robotics data for world models.
– Algorithmic multipliers (the 50% innovation bet).
Pure scaling alone is unlikely to reach full AGI consistency. Hybrids are the bet.
4. Outlook: Areas beyond in 2026, 2027–2028
– 2026 Breakthrough year for reliable world models + continual learning prototypes. Expect interactive Genie-like systems in agents/robotics (real-time physics simulation for training embodied AI).
Nested Learning / Titans-style memory becomes standard in agentic frameworks. On-device + persistent memory agents emerge. Scaling + early hybrids close gaps in planning/reasoning. “Omni-models” (text + vision + action + memory) start shipping.
– 2027 Convergence on unified foundation world models with persistent/continual memory. Agentic loops become robust (long-horizon tasks, self-correction). Robotics and scientific discovery accelerate via grounded simulation. Algorithmic efficiency + massive inference compute could yield systems that autonomously handle multi-week projects or invent in narrow domains.
– 2028+ Potential for more autonomous self-improvement loops if memory/world-model gaps close. Hassabis and others see this as the point where 1–2 breakthroughs compound into AGI-level consistency across reasoning, creativity, and real-world interaction. Progress will be measured by new evals (long-horizon agent benchmarks, Game Arena-style interactive tests) rather than just scale.
Hassabis and the frontier are clear—the era of just scale LLMs is transitioning to memory-augmented, world-model-driven, continually learning agentic systems. Scaling buys time and capability, but the algorithmic innovations (Nested Learning, Titans/Hope, Genie 3, inference-time reasoning) are the real accelerators for 2026–2028. The AI trajectory matches Hassabis’ push both branches (scaling and algorithms) hard philosophy.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.