
Nvidia has a structured data enablement strategy. Nvidia provides libaries, software and hardware to index and search data faster. The Indexing and retrievals are way faster 10-40X faster in most cases.
How cuDF + cuVS Work Together (The GTC 2026 “Ground Truth” Pipeline)
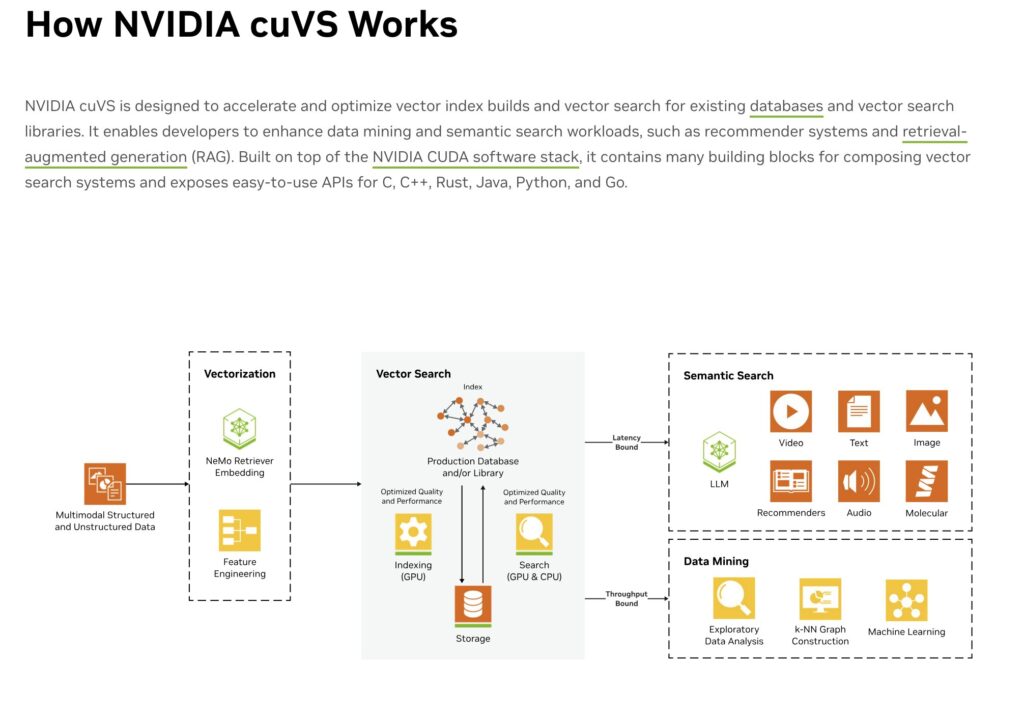
Unstructured data (PDFs, videos, logs, emails, sensor streams) → embedding model (NeMo, etc.).
cuVS indexes the embeddings (CAGRA/IVF-PQ) → semantic retrieval.
Retrieved context + facts → fed into cuDF DataFrames for cleaning, joining, aggregating, and turning into structured tables.
Result hundreds of zettabytes of “dark data” become queryable, trustworthy structured ground truth.
NVIDIA supplies GPU-accelerated software (cuDF + cuVS) and AI agents (NemoClaw) so enterprises, CSPs, and data platforms can securely transform their own hundreds of zettabytes of unstructured data (PDFs, videos, logs, emails, sensor streams, etc.) into structured, queryable ground truth inside their existing ecosystems.
Jensen explained:
cuDF (GPU-accelerated DataFrames) Turns raw unstructured data into structured tables/spreadsheets at massive scale. It accelerates open-source engines (Spark, Presto, DuckDB, Polars, etc.) and commercial platforms (Databricks, Snowflake, Starburst, EDB Postgres, etc.).
cuDF – GPU-Accelerated Pandas for Structured Data
What it is
cuDF is a Python library that provides a near-identical API to pandas but runs almost everything on the GPU. It is the direct analogue of “RTX for 3D graphics” but for tabular/structured data (Jensen’s words). Core Architecture Python layer → High-level pandas-like API (cudf.DataFrame, cudf.Series).
libcudf C++ backend → All heavy lifting (joins, groupby, sorts, string ops, etc.) is written in highly optimized C++ and compiled to CUDA kernels.
Columnar memory format → Built on Apache Arrow, enabling zero-copy interoperability with Spark, Polars, DuckDB, Arrow Flight, etc. No data format conversion overhead.
Memory management → RAPIDS Memory Manager (RMM) + Unified Virtual Memory (UVM) so datasets larger than GPU VRAM are automatically spilled to CPU/host memory.
Multi-GPU / distributed → Dask-cuDF and the RAPIDS Accelerator for Apache Spark let you scale to 10+ TB datasets across clusters.
Key Features & Operations of CUDF
Full pandas coverage: read/write CSV/Parquet/ORC/JSON, joins, groupby-agg, time-series, window functions, string methods (including wordpiece/tokenization for NLP).
cudf.pandas accelerator: Just run %load_ext cudf.pandas and your existing pandas code runs on GPU with automatic CPU fallback for unsupported ops.
Polars GPU engine: pl.DataFrame(…).collect(engine=”gpu”).
Native string & regex acceleration (critical for cleaning logs, PDFs, emails).
Null handling, categorical data, and decimal types all GPU-native.
Performance (real-world 2025-2026 numbers)
10–150× faster than CPU pandas on large datasets.
Apache Spark + cuDF: up to 5× faster queries, 10× better TCO on 10 TB data.
Snap (on Google Kubernetes Engine): 76% lower daily processing cost while analyzing 10 petabytes in <3 hours.
IBM watsonx.data + Nestlé: 5× faster workloads, 83% cost reduction.
Dell AI Data Platform: 3× faster overall.
cuVS (GPU-accelerated vector search) Handles the unstructured/vector side — embeddings, similarity search, retrieval — so AI can actually “understand” documents, videos, and logs.
CUVS Key Features
GPU-Accelerated Indexing Algorithms
Optimized GPU indexing enables high-quality index builds and low-latency search. cuVS delivers advanced algorithms for indexing vector embeddings, including exact, tree-based, and graph-based indexes.
Real-Time Updates for Large Language Models (LLMs)
cuVS enables real-time updates to search indexes by dynamically integrating new embeddings and data without rebuilding the entire index. By integrating cuVS with LLMs, search results remain fresh and relevant.
High-Efficiency Indexing
GPU indexing lowers cost compared to CPU-only workflows while maintaining quality at scale. Additionally, the ability to build large indexes out-of-core enables more flexible GPU selection and ultimately lower costs per gigabyte.
Scalable Index Building
For real-time applications and large-scale deployments, cuVS enables both scale-up and scale-out for index creation and search at a fraction of the time it takes on a CPU without compromising quality.
GPU-Accelerated Search Algorithms
cuVS transforms vector search by integrating optimized CUDA-based algorithms for approximate nearest neighbors and clustering, ideal for large-scale, time-sensitive workloads.
Real-Time Updates for Large Language Models (LLMs)
cuVS enables real-time updates to search indexes by dynamically integrating new embeddings and data without rebuilding the entire index. By integrating cuVS with LLMs, search results remain fresh and relevant.
Low-Latency Performance
cuVS provides ultra-fast response times for applications such as semantic search, where speed and accuracy are critical. Furthermore, support for binary, 8-, 16-, and 32-bit types means memory use is optimized for high-throughput applications.
High-Throughput Processing
GPUs handle hundreds of thousands of queries per second, making cuVS perfect for demanding use cases like machine learning, data mining, and real-time analytics.
CUVS Performance (2025-2026 benchmarks)
Index build is 40×+ faster than CPU DiskANN/Vamana
9× faster HNSW vs pgvector
22× faster CAGRA in Milvus
40× in Apache Lucene.
Query 8–20× higher throughput with dynamic batching + quantization
10× lower latency in high-volume scenarios (ads, trading).
Oracle Database 23ai 5× end-to-end
Google Cloud AlloyDB 9× HNSW
Weaviate: 8× index build.
How cuDF + cuVS Work Together (The GTC 2026 “Ground Truth” Pipeline)
Unstructured data (PDFs, videos, logs, emails, sensor streams) → embedding model (NeMo, etc.).
cuVS indexes the embeddings (CAGRA/IVF-PQ) → semantic retrieval.
Retrieved context + facts → fed into cuDF DataFrames for cleaning, joining, aggregating, and turning into structured tables.
Result hundreds of zettabytes of “dark data” become queryable, trustworthy structured ground truth.
NemoClaw agents (the enterprise OpenClaw Jensen launched) orchestrate the entire pipeline with privacy guardrails and sandboxing.
Real-world adoptions announced at GTC 2026 Apache Spark, Databricks, Snowflake, Presto, DuckDB, Polars, Velox.
IBM watsonx.data, Dell AI Data Platform, Google Cloud Dataproc, Oracle AI Database 26ai, Amazon OpenSearch, Milvus, Weaviate, FAISS.
Production wins Nestlé (5× faster), Snap (76% cost cut), medical datasets (Sofya/Biofy), petabyte-scale RAG.
Official Links for Deep Dives cuDF docs: https://docs.rapids.ai/api/cudf/stable/
cuVS docs: https://docs.rapids.ai/api/cuvs/nightly/
NVIDIA GTC 2026 live blog (adoption numbers): https://blogs.nvidia.com/blog/gtc-2026-news/
Vector-search optimization blog: https://developer.nvidia.com/blog/optimizing-vector-search-for-indexing-and-real-time-retrieval-with-nvidia-cuvs/
NemoClaw (enterprise version of open-source OpenClaw).
AI agents that automate the entire pipeline — ingestion, cleaning, embedding, structuring, and querying — with built-in privacy guardrails, sandboxing (OpenShell), and confidential computing (even the cloud operator cannot see the raw data). Jensen called this “the operating system for personal/enterprise AI.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.