
NVIDIA CEO Jensen revealed that not only does Space AI solve the AI energy scaling problem and the compute scaling problem, it also solves the data scaling problem.
AI scaling is the core principle driving modern AI progress: bigger is reliably better. When you train neural networks with more compute, more data, and the energy needed to run them, performance improves in smooth, predictable ways — following mathematical “power laws” discovered in 2020–2022 and tracked ever since by Epoch AI.
Here’s how the three ingredients work together:
Compute (FLOPs)
The total number of calculations during training.
10× more compute ≈ 10× bigger model or 10× more training steps.
Every 10× jump in compute has historically cut prediction error by a fixed percentage (power-law relationship).
Data (tokens)
The amount of high-quality text, code, images, video, etc. the model sees.
Models are “data-hungry”: roughly equal compute should be spent on model size and data volume (Chinchilla law).
More data = better knowledge, fewer hallucinations, stronger reasoning.
Energy
The hidden bottleneck. Training today’s frontier models burns gigawatt-hours (equivalent to a small city for months).
More cheap, abundant energy = you can run bigger clusters longer and keep training at massive scale without melting the grid.
ALL three legs of scaling will be handled by AI in Space. Jensen revealed that Space AI data centers will be used for video and image generation which will be used for generating unlimited synthetic data. It will also access 100 times more data than can be sent back to Earth.
Going from 10²³ → 10²⁵ FLOPs (roughly GPT-3 to GPT-4 class) turned a decent chatbot into something that could pass bar exams and write working code.
Another 100–1,000× scale-up (2026–2028) is expected to produce models that can do month-long expert work in one shot.
Elon Musk, XAI, SpaceX and Tesla will be able to use unlimited poker with an all-in scaling strategy to just buy the AI pot and win completely.
They can out-compute/out-energy/out-data everyone via vertical integration. This gives xAI/Tesla/SpaceX a realistic path to dominance in the AI race by 2028–2030 and a likely decisive lead through an intelligence explosion. It directly exploits AI scaling laws (predictable gains from more FLOPs, data, and effective compute) while positioning them for the fastest/most sustained version of an intelligence explosion as analyzed in the March 2025 Forethought paper Three Types of Intelligence Explosion (by Tom Davidson, Rose Hadshar, Will MacAskill).
Core Strategy Buying the AI Pot
Frontier model performance improves smoothly and predictably with
Compute (training/inference FLOPs)
Data (tokens + synthetic)
Energy (the ultimate bottleneck — more power = more chips running longer/bigger)
Epoch AI (as of late 2025) tracks:
Frontier training compute growing ~5×/year historically.
Algorithmic efficiency ~3×/year effective compute.
Capabilities Index +15.5 ECI/year (accelerating).
Power is the hard limit: largest clusters already at hundreds of MW; Earth grid additions are slow (1-2% yearly firm power growth).
Elon’s stack attacks this asymmetrically.
xAI data centers: “Superhuman” build speed (Jensen Huang: 19 days from install to training on Colossus vs. 1+ year industry norm; now scaling to 500k+ GPUs). No one else matches this velocity.
Tesla fleet inference: Millions of HW4/AI4 vehicles (dual-SoC, ~100-300 TOPS total per board depending on exact config; ~9M vehicles delivered by end-2025, growing fast). AI5 (2026+) claimed 5-50× perf. Opt-in distributed inference during idle time (parked, solar/Powerwall-powered) gives variable renewable access that monolithic grids can’t match — effectively 50-100%+ “extra” power without firm grid constraints.
Powerwalls + distributed: Add inference chips to home energy systems → tap intermittent solar/wind at scale. This bypasses grid buildout lags.
Space data centers (via SpaceX + xAI merger plans): Solar in orbit = constant power (no night/atmosphere/clouds), vast scale (1M+ satellite filings), launch costs crashing with Starship. Musk: cheapest AI compute in space within 2-3 years. 1,000–10,000× more power than Earth feasible; heat dissipation easier in vacuum; data beamed down or processed in-situ.
Data moat too. 100× more real-world video/observational data. Space AI could help simulate/synthesize 1,000× more for training.
Elon can supercharge the scaling laws. Bend it harder and faster than competitors (OpenAI/Microsoft, Google, Anthropic, China). Epoch notes power and data as 2030 and 2035 constraints and beyond. Space AI can allow both power to data by 1000 to 1 million times.
METR Time Horizons & Projections
METR’s “50% time horizon” = longest task (human expert effort) an AI completes with 50% success in one shot/ short agent run.
Claude Opus 4.6 ~14.5 hours.
Exponential growth and it is now doubling every 4 months.
Using your 4-month doubling (conservative vs. recent acceleration. 3 doublings/year = 8×/yr, 64×/2yr)
2028 (2 years / 6 doublings). 900 hours (37 days human-equivalent). AI agents autonomously handle month-long R&D/software projects at expert level.
2030 (4 years / 12 doublings). 57,000 hours (6.5 years). Multi-year projects (full chip design cycles, scientific discovery programs) in one run.
2032 (6 years / 18 doublings). 3.7 million hours (420 years). Century-scale human knowledge work compressed.
2034 (8 years / 24 doublings), 234 million hours (26,000 years). God-like on any serial cognitive task.
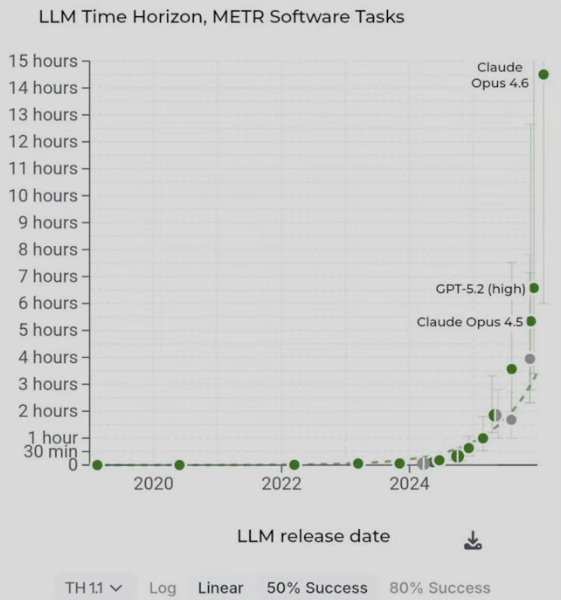
AI runs these much faster than humans once successful — often 10-100× wall-clock speedup. This crosses into full automation of AI R&D itself.
Link to Three Types of Intelligence Explosion
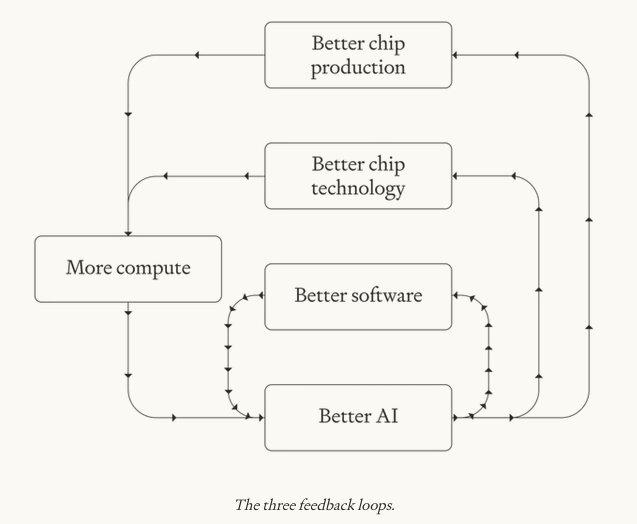
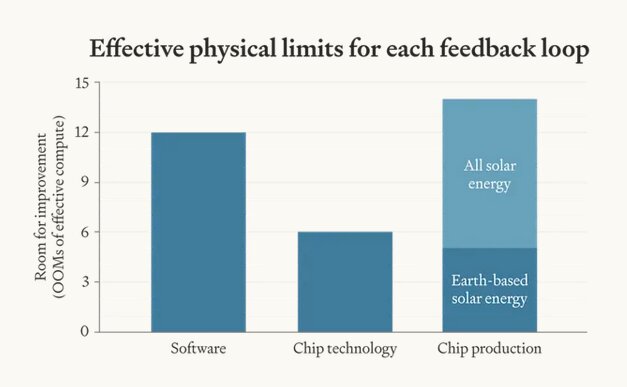
The paper identifies three feedback loops → three explosion types:Software-only (AI improves algorithms/post-training): Suddenest, but limited (~12-13 OOM effective compute gain).
AI-technology (software + chip design): Faster hardware too.
Full-stack (all + chip production via robots/factories/mining): Slowest start, most sustained (23-32+ OOM with space solar); power broadly distributed but favors industrial giants.
Elon’s integrated empire (Tesla chips/Dojo/energy/robots + xAI models + SpaceX launch/fab-in-space) is uniquely positioned for full-stack (or at least AI-technology) explosion. Vertical control shortens lags across loops. Space solar unlocks the highest physical limits. If they hit the METR projections via this scaling, they trigger the loop first and hardest — AI designs better chips/models, robots build more, space provides unlimited energy/data.
One entity (xAI/Tesla/SpaceX) pulls decisively ahead. Software-only would favor current lab leaders. Full-stack favors this stack. Power concentration in one (vertically integrated, US-based) player, but with massive real-world deployment (cars/bots/energy).
They have the strongest buy the pot hand in AI by far with a monopoly on space. No competitor has anything comparable.
Build velocity + hardware fleet + energy vertical + soon cheap orbital power + proprietary real-world data flywheel and soon orbital synthetic data and they will get competitive building their own chips with AI5 and they will get their fabs for compute and memory.
Epoch constraints (power ~GW-scale Earth limits by 2030) are exactly what space + distributed solves. By 2028-2030, if projections hold, capabilities hit transformative thresholds where the leading models self-improve faster than anyone can catch up.
Caveats (real risks, not cope)
Actual results of scaling can be slower or deliver less results.
Overhype on timelines (METR doublings could slow).
This is the logical endgame of the scaling paradigm + Elon’s moats. By 2030 the gap could be unbridgeable.
Current baseline (Feb 2026)
Frontier training compute: ~10²⁶ FLOPs (top closed models a few times higher)
METR 50% time horizon: 14.5 hours (Claude Opus 4.6 on complex software tasks)
1000× more compute + 1000× more energy + 1000× more data (mostly synthetic, ~70-80% of total)
This is the Epoch AI baseline projection for ~2029–2031.
What you get:Training runs of ~10²⁹ FLOPs (exactly what Epoch calls “feasible by end of decade”)
METR time horizon jumps to weeks to a couple of months of expert human work in one continuous run
Capabilities: Models that outperform today’s best humans on almost every cognitive task.
Think fully autonomous AI agents that can independently complete multi-week professional projects (entire large software systems, full scientific research pipelines, complex business strategy + execution).
Real-world impact: Automates the majority of white-collar cognitive work at expert+ level. Major economic transformation begins.
1,000,000× (one million times) more of each
This is extreme scaling territory (~10³² FLOPs), likely reachable in the mid-2030s with breakthroughs in energy (distributed + space-based) and synthetic data flywheels.
What you get:METR time horizon: years to centuries of human expert work compressed into single runs
Capabilities: Superhuman across the board — AI that can outperform all of humanity combined on any serial cognitive task. Full self-improving R&D loops (AI designs better AI, better chips, better robots, new physics experiments, etc.).
This is where the intelligence explosion becomes plausible or inevitable. The AI accelerates its own progress faster than humans can follow.
At this scale, synthetic data dominates (90%+), but the model must stay grounded in real-world feedback (robots, sensors, physical experiments) or it risks drifting into high-quality but sterile/less useful outputs.
Leading by 10× advantage in compute + energy + data (balanced scaling)
This is a massive edge — roughly equivalent to 12–18 months of normal industry progress compressed into one model generation. This is based on Epoch AI’s 2026 scaling tracker.
What it actually delivers
METR 50% time horizon → jumps from today’s ~14.5 hours to 2.5–5 days of expert human work in one continuous run.
Solves week-long professional tasks autonomously (full software features, scientific experiments, business plans with execution).
2–4× better than competitors on hard agentic benchmarks (SWE-bench, GAIA, SciCode, etc.).
Your AI can do what their next-next-generation models will do.
100× advantage in each
This is decisive / potentially game-over territory — ~2–3 years of normal progress in one jump (Epoch projects this scale around 2029–2031 for the leader).
What it delivers
METR time horizon → 10–40+ days (or even low months) of expert work in one shot.
Autonomous month-long R&D projects (design a new chip, run a full drug-discovery pipeline, invent and test new algorithms).
Outperforms all human experts combined on most serial cognitive tasks.
Full self-improvement loops start firing reliably.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.